opencv + c++でセピア調変換
c++でのセピア調変換のコードが出てこなかったので。。。
環境
macOS Big Sur 11.2.3Apple clang version 12.0.0
opencvインストール
筆者はmacなので以下macでの方法です。$ brew install opencv
opencvをインクルードしてビルド
ディレクトリ構成
├── sample.cpp├── CMakeLists.txt
├── lenna.jpeg
└── build/
準備
以下のようなcppファイルを用意。opencv2/opencv.hppをインクルードすると全てのopencvのライブラリをインクルードしていることになる。#include <iostream> #include <opencv2/opencv.hpp> using namespace std; using namespace cv; int main() { return 0; }
IDEでならもっと簡単に環境構築できるかもしれないが、筆者は差し当たりコマンドラインで実行できるようにした。
cmakeのためのbuildディレクトリを作成。
$ mkdir build
いつも通りg++でcppファイルをコンパイルしようとすると'opencv2/opencv.hpp' file not foundのようなエラーが出るので、cmake経由でビルドする。
$ cd build $ cmake .. . $ make $ cd .. $ ./build/main
参考:
MacにOpenCV(C++)環境を構築する - Qiita
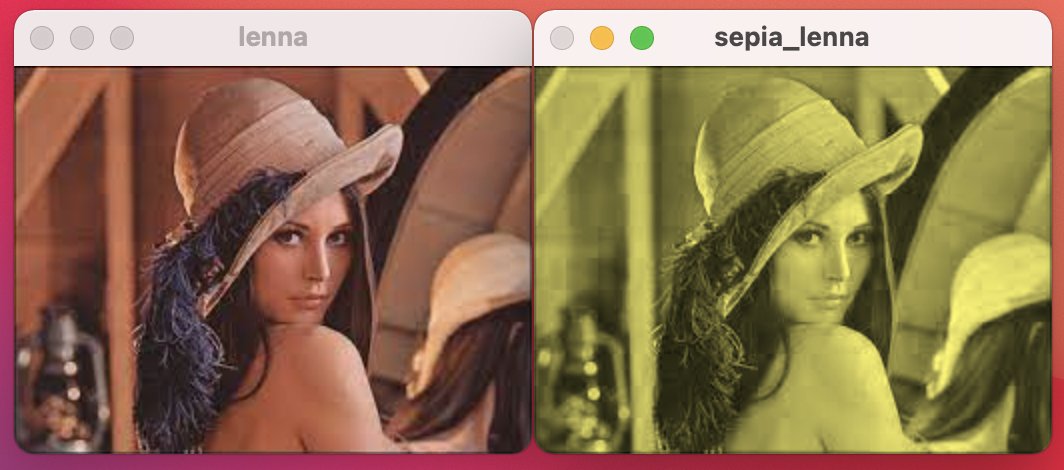
セピア調変換
#include <iostream> #include <opencv2/opencv.hpp> using namespace std; using namespace cv; int main() { Mat img = imread("lenna.jpeg"); // 画像の読み込み Mat hsv_img, sepia_img; cvtColor(img, hsv_img, COLOR_BGR2HSV, 3); // RGBからHSVに変換 for (int y = 0; y < hsv_img.rows; y++) { for (int x = 0; x < hsv_img.cols; x++) { hsv_img.ptr<uchar>(y)[3*x] = 29; // 色相(H)変更 hsv_img.ptr<uchar>(y)[3*x + 1] = 153; // 彩度(S)変更 } } cvtColor(hsv_img, sepia_img, COLOR_HSV2BGR, 3); // HSVからRGBに変換 imshow("lenna", img); // 画像の表示 imshow("sepia_lenna", sepia_img); // 画像の表示 waitKey(0); // 実行を終了しない return 0; }
RGB→HSV変換をすると、画像の多次元行列のRの部分にH、Gの部分にS、Bの部分にVが入るようになります。
確かにwikiによればセピアとはHSV(29°, 60%, 42%)なので、Hは29°、Sは256 × 60% = 153を代入すると画像がセピア調になります。
画像を表示する際には再びHSV→RGB変換をして元に戻しています。
Golang + Mysql + Dockerで環境構築したった
シュタインズゲートを最近初めて見て、ダルのような生き方をしたいと思いました。
前提知識
Golang
言わずと知れたGo言語の別称。Goだと海外では紛らわしいらしい。
Echo
Golang の webフレームワーク。簡単にルーティングなどができる。
Gorm
Go 版の Active Record。 Go のOR マッパー。
GOPATH
Go で開発をするにあたり必須の環境変数。必要なライブラリはGOPATHに全てインストールされる。
vi .bash_profile export GOPATH=/Users/sipporyusyon/Desktop/workspace/go
Docker
コンテナ型の仮想化ツール。OS までは仮想化しないので、Virtual Box とかより軽い。ちなみに Golang で書かれている。
ファイル構成
カレントディレクトリを /Users/sipporyusyon/Desktop/workspace/go とする。.
├── Dockerfile
├── docker-compose.yml
├── main.go
└── handler── create.go
各ファイル
docker-compose.yml
version: '3' services: app: build: . # docker-compose.yml はgo/ 直下に置いてるので . ディレクトリでビルドする container_name: go_app # 自由に決められる volumes: - ./:/go # dockerコンテナ上の変更をローカルのmacに保存 ports: - 1323:1323 # 開放するポート depends_on: # dbコンテナに接続する ビルドするのもdbコンテナが立ち上がってからになる - db db: image: mysql:latest # mysql のdockerイメージを取ってくる container_name: go_db # 自由に決められる volumes: - ./mysql_data:/var/lib/mysql # データ永続化のためのボリューム - ./sqls/init:/docker-entrypoint-initdb.d ports: - 3306:3306 # 開放するポート environment: MYSQL_ROOT_PASSWORD: docker_pwd # sqlのrootユーザーでログインする時のパスワード MYSQL_DATABASE: docker_db # sqlで初回起動時に作成されるデータベース名 MYSQL_USER: docker_user # sqlで初回起動時に作成されるユーザー名 MYSQL_PASSWORD: docker_user_pwd # sqlで初回起動時に作成されるユーザーのパスワード volumes: mysql_data: # ローカルのディレクトリにデータを保存
細かいことはこの記事を見てください。(別タブ開きます)
Dockerfile
FROM golang:1.11.2-alpine3.8 AS build # GolangのDockerイメージ取ってくる
WORKDIR /go # Docker上の作業ディレクトリ設定
ADD . /go # ローカルのファイルをdocker にコピー
RUN apk update && \
apk add --no-cache git && \
go get github.com/go-sql-driver/mysql && \ # go で sql 使うのに必要なライブラリ
go get github.com/labstack/echo/middleware && \ # echo インストール
go get github.com/jinzhu/gorm # gorm インストール
CMD ["go", "run", "main.go"] # main.go ファイル実行 後述するがmain.goでサーバーを立てる特に話すことはないですね。docker-compose.yml よりも先に Dockerfile の方が先に実行されるのは、考えれば当たり前ですが、最近知りました。
main.go
package main import ( "github.com/labstack/echo" "github.com/labstack/echo/middleware" "./handler" ) func main() { e := echo.New() // Middleware e.Use(middleware.Logger()) e.Use(middleware.Recover()) // Routes e.GET("/users", handler.ListUser) e.GET("/users/:id", handler.GetUser) e.POST("/users", handler.CreateUser) e.PUT("/users/:id", handler.UpdateUser) e.DELETE("/users/:id", handler.DeleteUser) // Start server e.Logger.Fatal(e.Start(":1323")) }
echo では echo インスタンスを作った後 e.start でサーバーを建てることができます。
ルーティングの中で handler パッケージの ListUser メソッドや CreateUser メソッドなど呼び出していますが、今回では CreateUser メソッドだけ触れます。
なお、echo 関連は基本この記事でコピペ勉強させていただきました。(別タブ開きます)
handler/create.go
package handler import ( "net/http" "github.com/labstack/echo" "github.com/jinzhu/gorm" _ "github.com/jinzhu/gorm/dialects/mysql" ) type User struct( Id int `gorm:"AUTO_INCREMENT"` Name string `gorm:"type:varchar(50);"` ) func gormConnect() *gorm.DB { db,err := gorm.Open("mysql", "docker_user:docker_user_pwd@tcp(docker.for.mac.localhost:3306)/docker_db") if err != nil { panic(err.Error()) } return db } func CreateUser(c echo.Context) (err error) { db := gormConnect() defer db.Close() u := &User{} if err := c.Bind(u); err != nil { return err } u.Name = "test" db.Table("User").Create(&u) return c.JSON(http.StatusCreated, u) }
まず、import 内で gorm, echo のライブラリを呼ぶ。今回 mysql に接続できればいいので, User の構造体は簡易なものにした。
gormConnect 関数内で mysql コンテナに接続。gormのOpen関数を使うことで接続する。docker から繋ぐのでは ホストの名前が localhost ではまずいらしく、一番ハマった。正しくは docker.for.mac.localhost。ポートは mysql コンテナのポート。
docker_user, docker_user_pwd, docker_db はdocker-compose.yml で定義した環境変数の値でおけ。
CreateUser 関数内で db インスタンスを受け取る。echo.Contect は echo でレスポンス返す時に使う変数...くらいにしか理解がありません。
u に User 型の変数を定義し、u.Name に値を代入。db.Table("User").Create(&u) で User テーブルがあれば、POSTリクエストがあった時、Userテーブル内に id が1、nameがtest のユーザーが作られるはずです。
確認
[sipporyusyon@MBP go] docker-compose up
コンテナを起動させる。
[sipporyusyon@MBP go] docker exec -it go_db bash
mysql コンテナ内に入る。
root@be9383fe56c8:/# mysql -u docker_user -h localhost -D docker_db -p # パスワードを聞かれるので入力(docker-compose.ymlで指定したdocker_user_pwd)
使用するユーザー名とデータベース名を指定して、mysql に接続。
mysql> CREATE TABLE User (Id int auto_increment, Name varchar(50));
Id と Name をカラムに持つ User テーブル作成。
コンテナを一度出て,
[sipporyusyon@MBP go] curl -v POST -H "Content-Type: application/json" "http://localhost:1323/users"
curl で CreateUser のある url へ POST リクエストを送る。
無事Userテーブルに testユーザーが作られたら成功。
あとがき
ここまで書くのに2時間かかって、現在夜の3時...何がやばいって平日の木曜なのがやばいですね。
rails + postgresQL + Docker-composeで環境構築したった
herokuにデプロイしたくて、クレジットカード登録するのめんどくさくて、postgresQL入門しました。
事前準備
mkdir myapp # 好きな名前でどうぞ cd myapp gem install rails rails new example_app -d postgresql # 好きな名前でどうぞ
myappディレクトリに以下のファイルを追加 ( app, bin, config などと同列に置く )
Dockerfile
FROM ruby:2.4-alpine ENV LANG C.UTF-8 ENV HOME /app WORKDIR $HOME COPY Gemfile $HOME COPY Gemfile.lock $HOME RUN apk update -qq && apk add --no-cache build-base tzdata libxml2-dev libxslt-dev alpine-sdk postgresql-dev nodejs RUN bundle install EXPOSE 3000
Dockerfileはこんな感じです。似たような記事の dockerファイルを見ると、
RUN apt-get install -y build-essential libpq-dev
とか書かれたりしてて、こっちはUbuntuベースのdockerファイルだそうですね。今回のはalpine-linuxベースのdockerファイルで、なんでも容量が劇的に小さくなるそう。node.jsが入ってるのは僕がこの後reactを使いたいからですね!使わないなら削除してもらって大丈夫です。
docker-compose.yml
version: '3' services: rails: build: . container_name: example_rails tty: true stdin_open: true ports: - 3000:3000 environment: - "DATABASE_HOST=database" - "DATABASE_PORT=5432" - "DATABASE_USER=user_name" #好きな名前でどうぞ - "DATABASE_PASSWORD=your_password" #好きな文字列でどうぞ volumes: - .:/app:cached - /app/.git - /app/node_modules - /app/log - /app/tmp command: rails s -b 0.0.0.0 -p 3000 --environment development depends_on: - database links: - database database: image: postgres container_name: example_db volumes: - datavol:/var/lib/postgresql/data environment: - "POSTGRES_USER=user_name" # 上で設定したものと同じ - "POSTGRES_PASSWORD=your_password" # 上で設定したものと同じ ports: - 5432:5432 volumes: datavol:
postgresQLのデータ永続化については、
datavol:/var/lib/postgresql/data
の部分の記載で実現できています。dockerのボリュームとは、データを永続化する場所のことで、ポスグレコンテナの中では volumes と指定している場所です。
(ホストのディレクトリ):(コンテナ内のディレクトリ) の書き方なので、今回の場合だと、example_dbコンテナの/var/lib/postgresql/dataにあるデータは、ホストのdatavolディレクトリに保存され、コンテナを削除してもホストにデータが残っている、ということです。
Gemfile
source 'https://rubygems.org'
git_source(:github) do |repo_name|
repo_name = "#{repo_name}/#{repo_name}" unless repo_name.include?("/")
"https://github.com/#{repo_name}.git"
end
# Bundle edge Rails instead: gem 'rails', github: 'rails/rails'
gem 'rails', '~> 5.1.5'
gem 'pg'
# Use Puma as the app server
gem 'puma', '~> 3.7'
# Use SCSS for stylesheets
gem 'sass-rails', '~> 5.0'
# Use Uglifier as compressor for JavaScript assets
gem 'uglifier', '>= 1.3.0'
# Use CoffeeScript for .coffee assets and views
gem 'coffee-rails', '~> 4.2'
# Turbolinks makes navigating your web application faster. Read more: https://github.com/turbolinks/turbolinks
gem 'turbolinks', '~> 5'
# Build JSON APIs with ease. Read more: https://github.com/rails/jbuilder
gem 'jbuilder', '~> 2.5'
# Use Redis adapter to run Action Cable in production
# gem 'redis', '~> 3.0'
# Use ActiveModel has_secure_password
# gem 'bcrypt', '~> 3.1.7'
# Use Capistrano for deployment
# gem 'capistrano-rails', group: :development
group :development, :test do
# Call 'byebug' anywhere in the code to stop execution and get a debugger console
gem 'byebug', platforms: [:mri, :mingw, :x64_mingw]
end
group :development do
# Access an IRB console on exception pages or by using <%= console %> anywhere in the code.
gem 'web-console', '>= 3.3.0'
gem 'listen', '>= 3.0.5', '< 3.2'
# Spring speeds up development by keeping your application running in the background. Read more: https://github.com/rails/spring
gem 'spring'
gem 'spring-watcher-listen', '~> 2.0.0'
gem 'pry-rails'
gem 'pry-doc'
gem 'pry-byebug'
gem 'pry-stack_explorer'
end
# Windows does not include zoneinfo files, so bundle the tzinfo-data gem
gem 'tzinfo-data', platforms: [:mingw, :mswin, :x64_mingw, :jruby]
大体は rails のデフォルトのgemfileと変わらないと思うのですが、一つ大きな違いが。
gem 'pg' の存在です。こいつがないと postgresQL で Active Recordが使えません。
代わりに gem 'sqlite3' が消えてます。これを入れたまま heroku にデプロイしようとするとエラーが出ます。
database.yml
default: &default adapter: postgresql encoding: unicode username: <%= ENV.fetch('DATABASE_USER') { 'root' } %> password: <%= ENV.fetch('DATABASE_PASSWORD') { 'password' } %> host: <%= ENV.fetch('DATABASE_HOST') { 'localhost' } %> port: <%= ENV.fetch('DATABASE_PORT') { 5432 } %> # For details on connection pooling, see Rails configuration guide # http://guides.rubyonrails.org/configuring.html#database-pooling pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> development: <<: *default database: example_app_development # rails new で決めたアプリ名 test: <<: *default database: example_app_test # rails new で決めたアプリ名 production: <<: *default database: example_app_production # rails new で決めたアプリ名 username: example_app password: <%= ENV['EXAMPLE_APP_DATABASE_PASSWORD'] %>
実行コマンド
ファイルを全て設置し終わったら、docker-compose up
と実行してください。初回だと10分ぐらいかかりますが、これで rails と postgresQL のサーバが立つはず。
さ、Typescriptの勉強しよ....
プログラミング200日目
現状
Q & A 方式で行きます
- プログラミングに今どれだけ時間を割いているか?
A. 週50時間程度。大学休学中。 - プログラミングへのモチベーションは今どれぐらいあるのか?
A. かなり高い...レビューなどで自分の技術力の成長をすぐに実感できるところもそうだが、単純にプログラミングが楽しい。 - プログラミングの具体的にどのような点が楽しいのか?
A. webサイトに機能を追加するというのが、いまだに自分にとって新鮮で、面白い体験であるという点。
機能を追加するたびにコードの工夫を試行錯誤する過程や、動いた時の軽い達成感。
レビューによって自分の知識が広がり、次の開発にすぐに活かせられるので、自分の成長を感じやすい点。 - 将来プログラマーになるのか?
A. 微妙。プログラマーとして大手に勤める線が一番無い。
面白そうな事業に立ち上げ期から参加するか、自分でそういうものを立ち上げるか。
プログラミングを必ず使いたいと思っている。もともと物理学者になりたかったので、
物理とプログラミングが絡めば最高なのにと思う。
neo4j + rails でリレーション色々
neo4jrbのリレーション問題
どうも!記事2本目からいきなりマニアックなところに行ってしまいました。qiitaに書いても良かったけどせっかくなのでここに。開発でrails + neo4jを使い始めて一ヶ月ちょい、neo4jrbの基本的な操作をまとめました。active_rel 使わず、active_nodeオンリーです。間違ってる可能性めっちゃあります。ご注意を。
リレーション云々する前に
model同士の関係性を明記する必要がありますね
# user.rb class User include Neo4j::ActiveNode # 省略 property :name, type: String property :email, type:String has_many :out, :edit, type: :user_articles, model_class: :Article # 省略 end
# article.rb class Article include Neo4j::ActiveNode # 省略 property :title, type: String property :content, type: String has_one :in, :author, type: :articles_user, model_class: :User, unique: true #省略 end
has_manyとかhas_oneのオプションについて左から説明すると、
- :out, :in => リレーションの向きです。:inに矢印が刺さるので、今回だとUserからArticleへ矢印が伸びています。
- :edit, :author => rails内でリレーションを呼び出すメソッド(的な?)の名称です。このメソッドをモデルのインスタンスに繋げると、紐づいているインスタンスが配列で帰ってきます。
tom = User.find_by(name: "tom") tom.edit # => [article1, article2, article3] article = Article.find_by(name: "article2") article.author # => [tom]
- :article_user, :user_articles => リレーションの名称です。(neo4j browserで確認できるやつ) しかし、リレーション名は一つしか定められないので、矢印が出ている方(:outの方)に書いた:typeがリレーション名になります。:inの方のモデルに書くtypeに意味があるのかは知りません。追記するかも。とりあえず明示的に対応させておきましょう。
- model_class => そのままです。リレーション貼る相手のモデル名になります。
- unique: true => 二つのノードの組み合わせが同じときにはリレーションを新しく作りません。今回の場合で言えば、tom と article1 の間には、user_articlesリレーションは最大一つまでということです。
リレーションを張ろう
まず前提として、neo4jrbではリレーションは配列のように扱います。今回の場合で言えば、tomに結びついているarticle達は、tom.editという配列の中に入っています。新しくArticleモデルのインスタンス(ノード), article4をtomと紐づけたいときは、tom.editの配列の中に入れてやればいいのです。つまり、
article4 = Article.find_by(name: "article4") tom.edit << article4
こうです。これでリレーションが張れました。調べても出てこねえと思ってたら、公式に普通に乗ってました。説明「you can create associations」のみ。。。。
リレーションを貼る方法がもう一つあって、
article4 = Article.find_by(name: "article4") tom.edit = article4
これでもいけます。上のと何が違うかというと、tomに紐づいているノードの数が違います。上は、tomに3個Articleのノードが紐づいているとして、4個目を追加する操作ですが、下は既存の3個のリレーションを切って、新しく一個(article4)とリレーションを張ります。配列の更新と思えばわかりやすいかも。上はtom.edit配列にarticle4をpushしてますが、下はtom.edit配列を要素をarticle4だけの配列にする操作です。
リレーションを切ろう
これも配列の操作と考えれば理解できると思います
リレーションを全部切るとき
tom.edit = nil
tom.editを空の配列にすればtomからはuser_articleリレーションは一つも張られていない状態になります。
リレーションを一部切るとき
tom.edit = tom.edit.to_a - tom.edit.where(title: "しっぽりゅーしょん").to_a
tom.edit配列から何個か要素を取り除けばいいので、配列の引き算したものをtom.editにまた代入してやればOKです。
この場合では、tomの書いた記事の中から、タイトルが「しっぽりゅーしょん」の記事とtomとのリレーションを切りました。
しっぽりゅーしょん
「しっぽりゅーしょん」とは?
「しっぽり」...「しっぽり」という言葉が最近好きになってよく使ってます。使い方としては「しっぽりと雨の音を聞く」っていう感じかな。「しみじみ」だと本当は聞き入ってる自分に酔ってる感が出るけど、「しっぽり」はもう完全に没入しちゃってます。夢中で噛み締めてます。そんな「しっぽり」と僕の心に響いた事柄を、このブログではつれづれに書くつもりです。僕の心に響けばいいので、記事のジャンルは様々です。だいたいアニメ、読書、プログラミング、音楽、物理あたりになるのかなー。ちなみに「しっぽりゅーしょん」に関しては語感で決めました。この語感がしっぽりと響いたのです。なんかブログ見づらっと思われるのは僕がhtml下手くそだからです。これから頑張ります。拙い文章ですがどうぞ末長いお付き合いを!